Google公司的三驾马车GFS、Bigtable和MapReduce经常被大家看作是云计算的经典之作,Amazon公司的Dynamo和开源项目Hadoop也是云计算世界里的明星产品,实际上从技术角度来看它们都属于分布式系统的范畴。
分布式文件系统是如何发展起来的呢?
从20世纪70年代诞生至今,大致上可以将分布式文件系统的发展历程划分为四个阶段。1990年之前的分布式文件系统主要以提供标准接口的远程文件访问为目的,比较关注系统性能和可靠性。这一阶段的典型代表包括Sun公司研制的NFS(NetworkFile System)和美国卡内基梅隆大学开发的AFS(Andrew File System)。
1990年到1995年期间,互联网逐步得到推广应用,网络中传输实时多媒体数据的需求和应用也逐渐流行,这一阶段出现了不少为了实现上述需求而开发设计的分布式文件系统,例如加利福尼亚大学研制的xFS(x File System)和IBM公司针对AIX操作系统开发的TigerShark。
1995年到2000年期间,网络技术和存储技术持续发展,NAS和SAN等新的存储技术开始得到大量应用,与之相应的分布式文件系统也应运而生,例如美国明尼苏达大学研制的GFS(Global File System)和IBM公司在TigerSpark基础上开发的GPFS(General Parallel File System)。
进入21世纪以来,随着网格计算和云计算技术的发展,以Google公司为代表的软件公司和研究机构针对Web应用的特色,陆续推出了新型的分布式文件系统。这其中最为著名的当属Google公司的GFS(Google File System)和Hadoop开源项目的HDFS(Hadoop Distributed File System)。
注意上面提到了两个GFS,一个是明尼苏达大学研制的Global File System,另一个是Google公司开发的Google File System,后续我们提到的GFS都是特指后者,不再专门说明。
看起来,好像进入21世纪之后的分布式文件系统才与云计算产生了交集,是这样吗?
应该说,GFS和HDFS都是在云计算时代应运而生的产物,它们与传统的分布式文件系统有很大的不同,更能够满足云计算的需求。
但是,GFS的新颖之处并不在于它采用了多么令人惊讶的新技术,而在于它采用廉价的商用计算机集群构建分布式文件系统,在降低成本的同时经受了实际应用的考验。
与传统的分布式文件系统相比,GFS有哪些新的设计需求呢?
在性能、伸缩性、可靠性等方面,GFS的设计目标与传统的分布式文件系统没有什么区别;但是考虑Google各种应用的实际情况后,GFS在许多方面的设计目标又具有鲜明的特色。这主要体现在下述方面。
(1)Google的数据中心均采用廉价的计算机和IDE硬盘构建,因此硬件故障是一种常见的状况,在软件设计上必须提高容错能力。
(2)系统需要处理数以百万计的文件,大多数是100MB或更大,其中出现GB级别的文件也不奇怪,必须在设计时充分考虑这些因素。
(3)系统主要考虑支持两种读操作:大规模数据流读和小规模随机读。前者通常连续读取1MB或更多数据,后者通常读取几kB数据。
(4)系统中存在两种写操作:大规模顺序写和小规模随机写。前者通常连续写入1MB或更多数据,需要在设计时考虑性能优化。
(5)经常会出现多个应用程序同时向同一个文件进行追加写操作,必须保证这些并发操作的正确性。
(6)希望系统在针对大数据量操作时获得高性能,不关注单个读写操作所花费的时间。
GFS为应用程序提供了哪些访问接口?
GFS提供了一个类似传统文件系统的接口,按照层次型的目录树来管理文件,并提供传统的Create、Delete、Open、Close、Read和Write操作。除此之外,GFS还专门提供了Snapshot和Record Append两种操作。其中Snapshot以最小的开销创建一个目录或文件的副本,Record Append则用来保证多个应用程序同时对文件进行追加写操作时的正确性。
GFS采用了怎样的系统架构?
如图1所示,一个GFS的集群包括一个主服务器(master)和多个块服务器(chunk server),能够同时为多个客户端应用程序(Application)提供文件服务。每个服务器或应用程序都是运行在Linux服务器中的一个进程,只要性能允许,可以将服务器进程和应用进程运行在同一个物理服务器上。
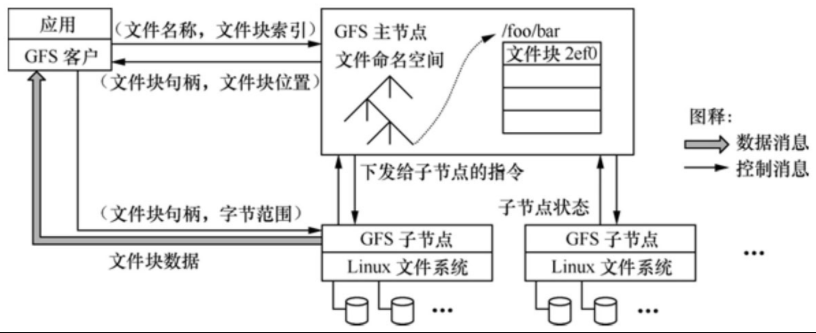
图1 GFS的系统架构
GFS中文件划分为固定大小的块,每个块在创建时由主服务器分配一个64位的句柄。块服务器将块以Linux文件的形式保存在本地硬盘上,并通过句柄实现对其指定的字节范围进行读写的操作。缺省情况下,GFS对每个块在三个不同的块服务器上保持三个备份,用户也可定制备份策略。
主服务器负责维护所有文件系统的元数据,包括命名空间、存取控制信息、文件和块的映射关系以及块的物理位置等。主服务器还负责管理文件系统,包括块的租用、垃圾块的回收以及块在不同块服务器之间的迁移。此外,主服务器还周期性地与每个块服务器通过心跳消息交互,以监视运行状态或下达命令。应用程序采用GFS提供的API函数接口通过与主服务器和块服务器的交互来实现对应用数据的读写,应用与主服务器之间的交互仅限于元数据,所有的数据操作都是直接与块服务器交互的。
GFS中应用和块服务器都没有针对数据采用缓存机制。绝大多数应用的流数据都是大型文件,因此在客户端无法采用数据缓存机制;而块服务器在Linux文件中已经采用了缓存机制,因此也不需要重复实现块的缓存了。当然,客户端针对元数据还是采取了缓存机制。
块的大小是如何设计的?
这是一个关键设计参数,GFS选择了64MB,该方案优点如下。
(1)降低了客户与主服务器之间的交互。对于在同一块之内读写操作需要的块服务器信息,客户只需要向主服务器请求一次就可以了,因此降低了客户与主服务器之间的交互。由于GFS的应用大多是面向大文件的,因此这个优点体现得很明显。
(2)降低了集群中的网络负荷。由于客户的读写操作大多被限制在同一块服务器之内,客户就不需要建立与多个块服务器的TCP连接,因此降低了网络负荷。
(3)减少了主服务器中元数据的存储容量。该方案的缺点如下:如果多个客户同时访问一个仅有几个块组成的小文件的话,存储该小文件的块服务器就会成为性能瓶颈。由于Google公司实际应用中绝大多数操作都是对大数据文件的读取,因此并没有出现这样的情况。
GFS的读操作是如何实现的?
读操作的步骤如下。
(1)客户根据指定位置和块大小计算得到文件中的块索引;
(2)客户将文件名和块索引发给主服务器查询对应的块服务器及句柄;
(3)客户将这些信息缓存在本地;
(4)客户向最近的块服务器发送读请求,包括块句柄及读取范围;
(5)块服务器返回客户要求读取的块内容。GFS的写操作又是如何实现的?
如图2所示,写操作包括7个步骤:
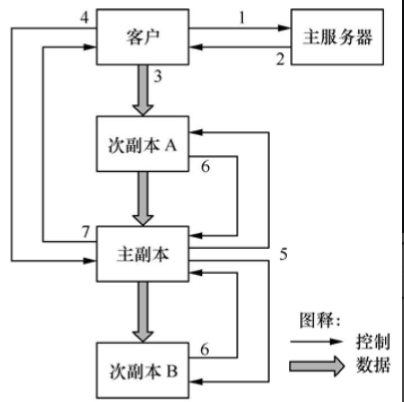
图2 GFS的写操作
(1)客户向主服务器查询写入块对应的主副本及次副本所在的块服务器,主服务器通过租约从多个块服务器中选择主副本。
(2)主服务器向客户返回写入块的位置信息。
(3)客户将写入数据推送到所有副本上,每个块服务器将这些数据保存在内部缓存中,直到数据被使用或过期。
(4)客户向主副本所在的块服务器发送写请求。
(5)主副本将客户的写请求传递到所有的次副本。
(6)写入完成后,各次副本将完成情况反馈给主副本。
(7)主副本将完成情况反馈给客户,如果出错则重复(3)~(7)步骤。
HDFS的架构是怎样的?
如图3所示,一个HDFS的集群包括一个名称节点(NameNode)和多个数据节点(DataNode),能够为多个客户程序(Client)提供服务。HDFS采用Java语言开发,因此任何支持Java的计算机都可以用来部署NameNode和DataNode。
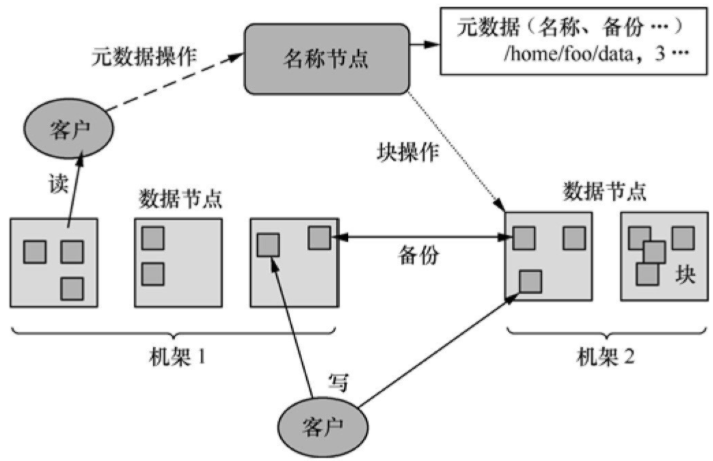
图3 HDFS的架构
HDFS内部将文件划分为若干个数据块,每个文件都存储为一系列的数据块,除最后一个外所有数据块的大小是相同的。缺省情况下,HDFS同时保存每个数据块的三个副本。
NameNode管理文件系统的命令空间,并维护文件到数据块的映射关系。DataNode负责处理客户程序的文件读写请求,并在NameNode统一调度下进行数据块的创建、复制和删除工作。
大型的HDFS集群一般跨越多个机架,不同机架之间通过交换机通信。一般将数据块的不同副本存放在不同的机架上,这样可以有效防止整个机架失效时数据的丢失,还可以在执行读操作时充分利用多机架的带宽实现负载均衡。
HDFS的读操作是如何实现的?
如图4所示,客户程序通过调用FileSystem对象的open()方法打开希望读取的文件DistributedFileSystem实例,后者通过远程进程调用访问NameNode得到文件起始块的位置。DistributedFileSystem实例返回一个输入流FSDataInputStream对象给客户程序以读取数据,该输入流对象专门封装一个DFSInputStream对象管理NameNode和DataNode。
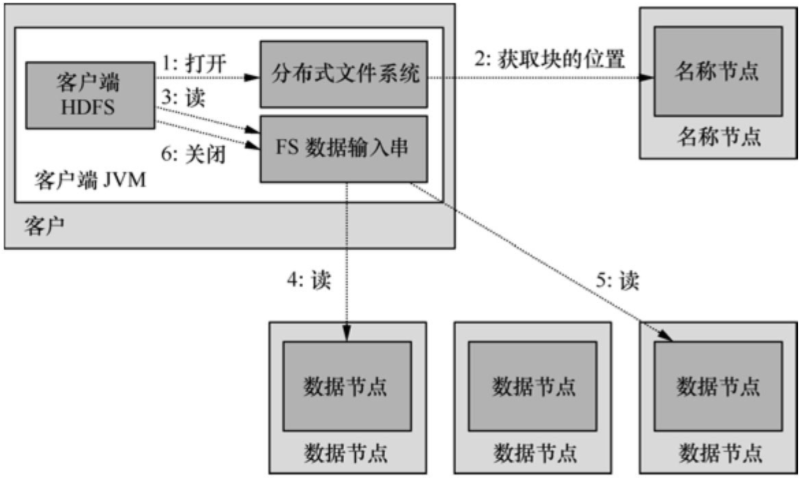
图4 HDFS的读操作
客户程序对该输入流对象调用read()方法,DFSInputStream对象即连接到距离最近的DataNode,通过反复调用read()就可以将数据块从DataNode传输到客户程序。到达块的末端后,DFSInputStream会关闭与该DataNode的连接,转而寻找下一个块的最佳DataNode。所有的数据块都读取完成后会调用FSDataInputStream对象的close()方法结束本次读操作。
HDFS的写操作又是如何实现的?
如图5所示,客户程序通过对DistributedFileSystem对象调用create()方法来创建文件,该对象同时对NameNode创建一个远程进程进程调用,在文件系统的命名空间中创建新文件。之后DistributedFileSystem向客户程序返回一个FSDataOutputStream对象,由此客户端开始写入数据。同时还会封装一个DFSOutputStream对象负责管理NameNode和DataNode。
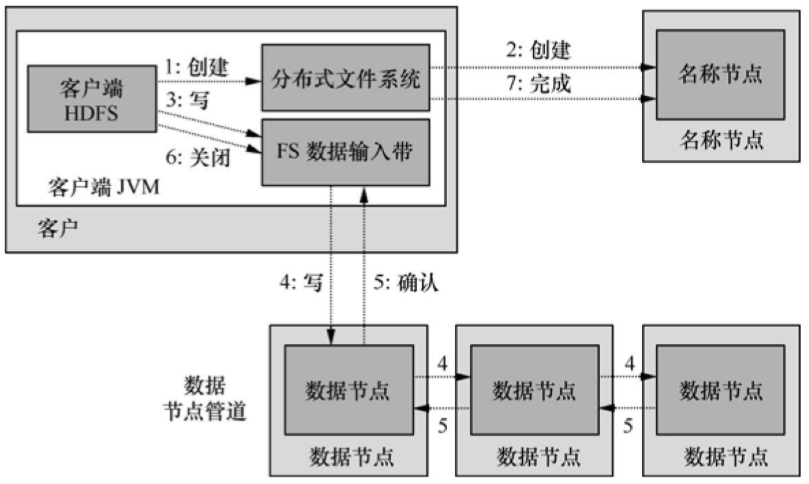
图5 HDFS的写操作
在数据写入过程中,DFSOutputStream将写入数据划分为多个数据包,并采用数据队列方式向多个DataNode写入副本,收到确认消息后继续上述过程写入其他数据块。所有数据块写入完成后会调用close()方法结束本次写入操作,并通知NameNode。
看起来HDFS与GFS非常相似啊,它们是什么关系呢?
Google在一份公开发布的论文中介绍了GFS的基本原理,但是并没有公开其源代码,Hadoop开源项目参考GFS公开的设计文档设计实现了HDFS,所以两者看起来是非常相似的。
一般认为HDFS是GFS的一个简化版的实现,两者有很多相似之处,例如都采用单主服务器和多数据服务器的架构、都采用数据块的方式来组织和管理文件。但是两者还是有不少差异的,例如HDFS不支持Record Append和Snapshot操作。


